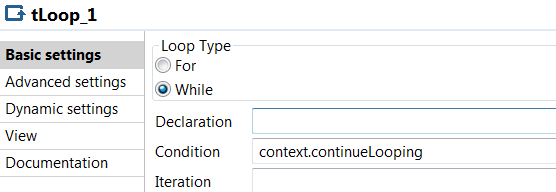
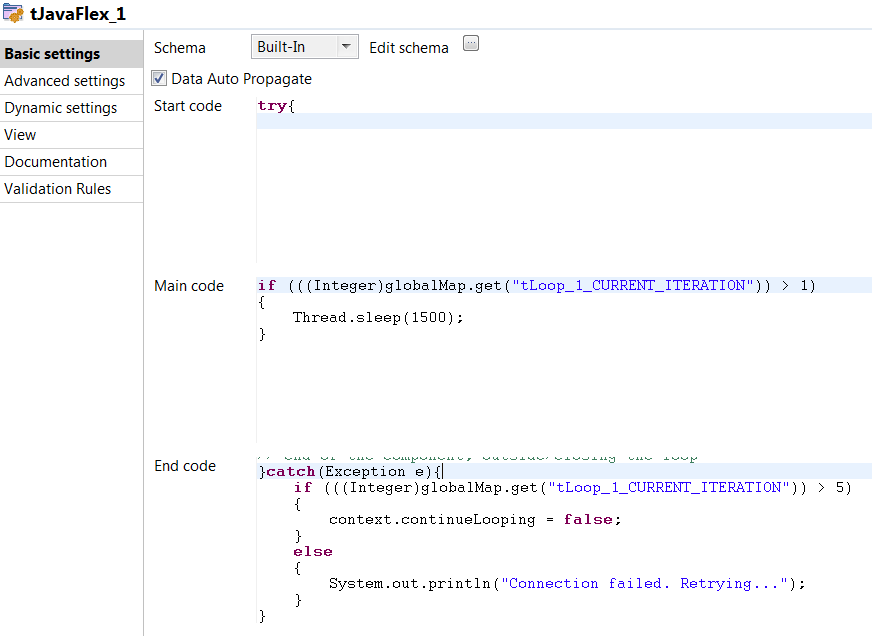
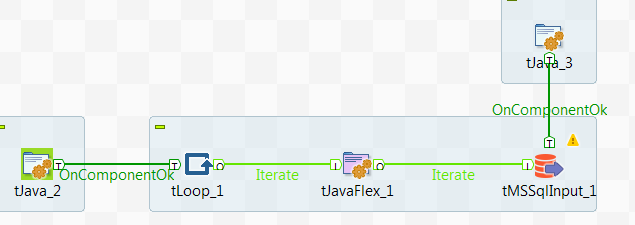
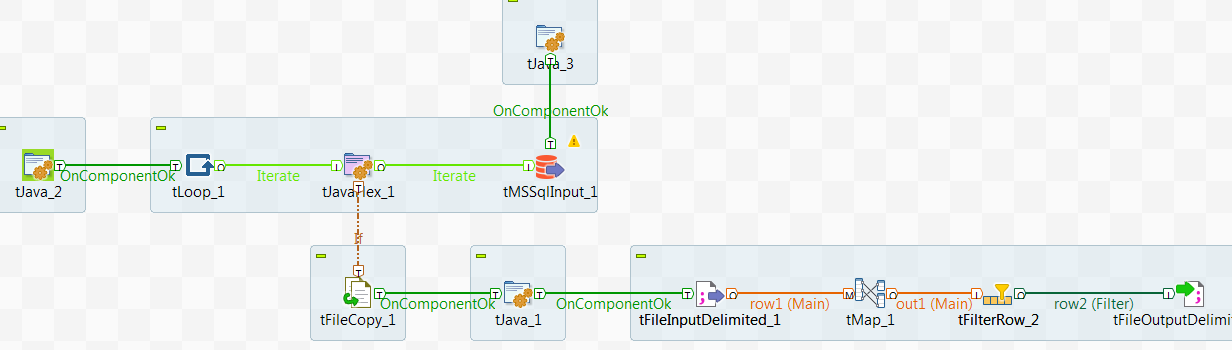
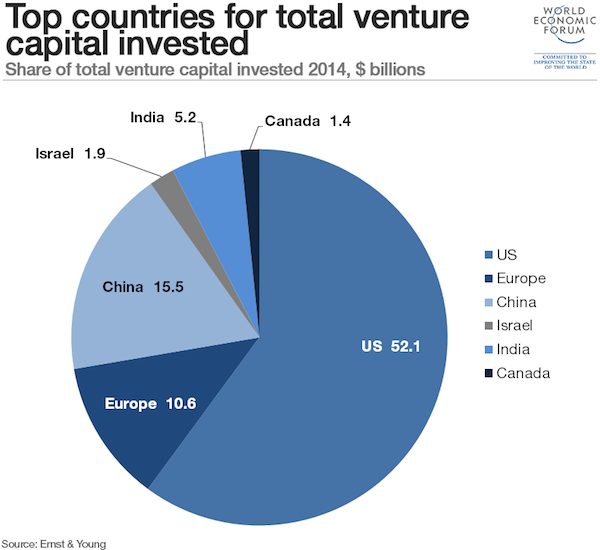
With SQL Server 2016 we are finally able to analyze and query JSON data. It is not that often I use XML, but JSON is so much used it is about time we can use it in SQL Server. In this entry I’ll let you follow me as I take a first look at it using some data from New York Times.
New York Times has a web app called Chronicle, which lets you see how many articles has mentioned specific words and this data you can also export as JSON. I chose to use the words Radio, Televion, Mail and Internet and downloaded one JSON file per word (for some reason it doesn’t work to get the data for several terms at once). I also chose to remove one of the sets of square parenthesis since our graph_data only will have one term and not a list of terms. I end up with four files that looks like this.
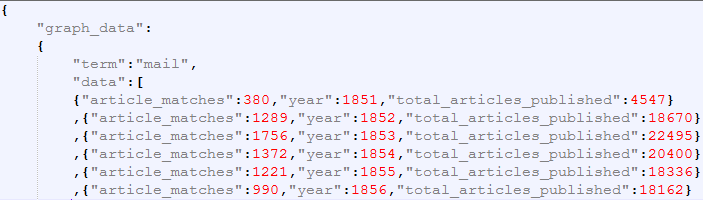
So the graph_data has a term that in our case is mail, radio, television and internet and an array of data which has the number of articles containing the number of articles with the term, the year and the total number of articles published in that year so we for example can calculate a percentage of how many articles the term was in.
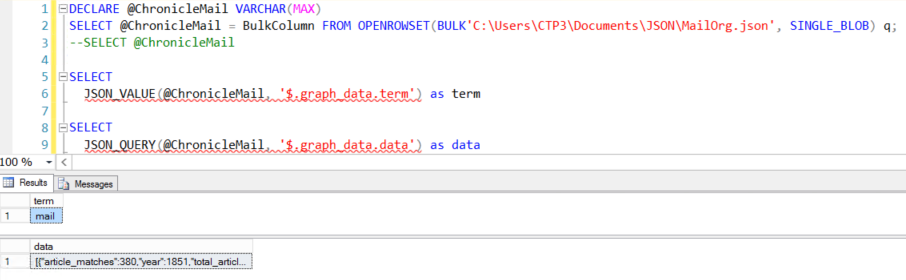
In order to read the JSON from the file I first load the entire file into a variable using the following code
DECLARE @ChronicleMail VARCHAR(MAX)
SELECT @ChronicleMail = BulkColumn FROM OPENROWSET(BULK'C:\Users\CTP3\Documents\JSON\MailOrg.json', SINGLE_BLOB) q;
SELECT @ChronicleMail
The last line selects the text so we can have a look at what is saved in the variable, which basicly is just one long string.
Not so interesting so far, but lets start using the new JSON functions. The JSON_VALUE function returns one scalar value from a JSON string. If you try using JSON_VALUE on something returning an array you will get a NULL returned. To get an array returned you must use the JSON_QUERY function. This is fine, but if you want to insert your data into a table the function you want to use is the OPENJOSN that lets you reference some array in your JSON and then return the elements.
In our case the data is an array so lets call OPENJSON and call it on the data.
SELECT
*
FROM OPENJSON(@ChronicleMail, '$.graph_data.data')
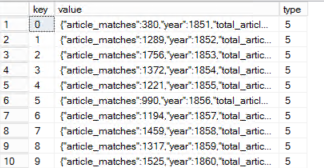
From the result set we can see that we now have one row per year in our data. Now that is cool and all, but we kind of want the values in different columns, not the entire JSON in a column with name value. To fix this you can add a WITH clause after the OPENJSON function.
SELECT
[NumberOfArticles]
,[TotalArticles]
,[Year]
FROM OPENJSON(@ChronicleMail, '$.graph_data.data')
WITH(
[NumberOfArticles] int '$.article_matches',
[Year] int '$.year',
[TotalArticles] int '$.total_articles_published'
)
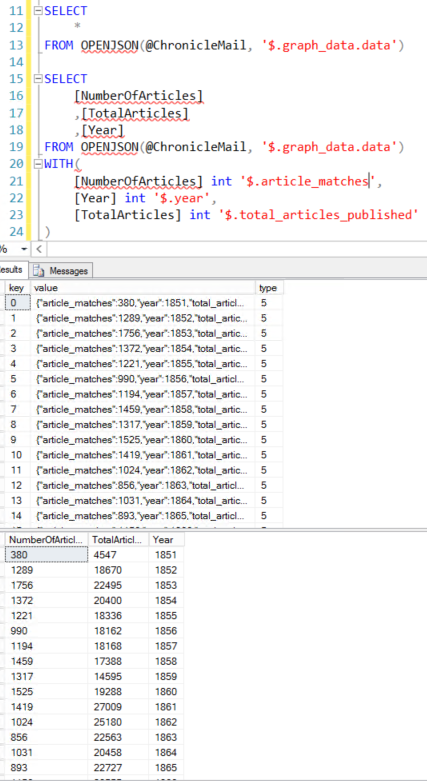
Excellent! We now have the data in a table structure and we can insert into an actual table or do whatever we want with it. I wanted to add the term to the data so I ended up just joining it to this dataset using the JSON_VALUE function to pull only the term.
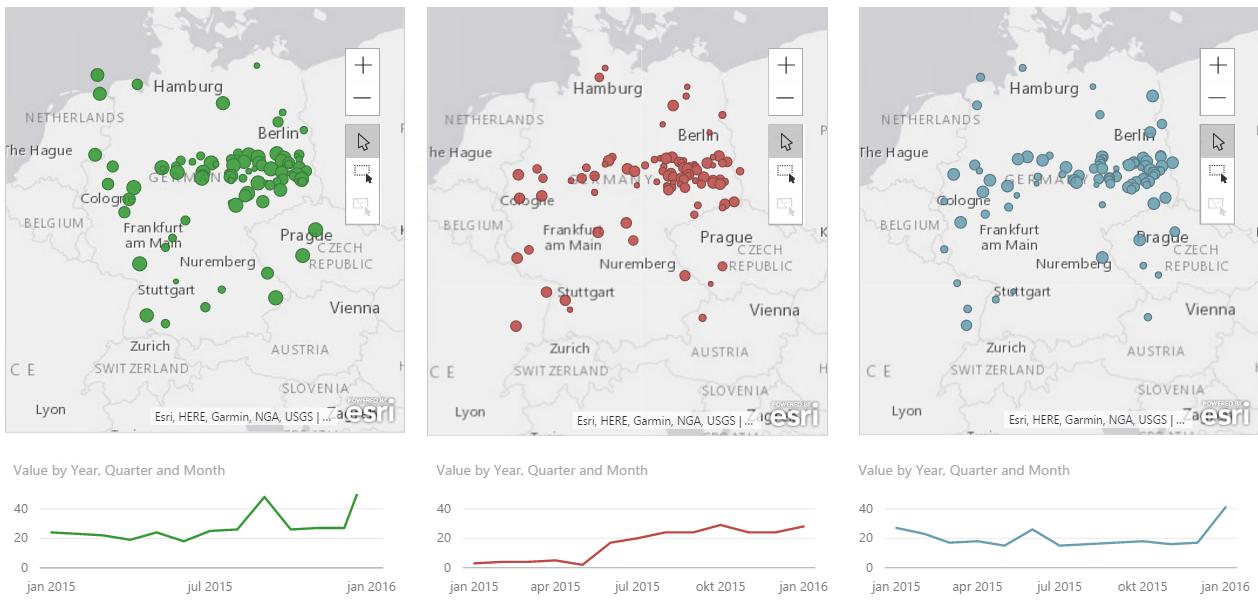
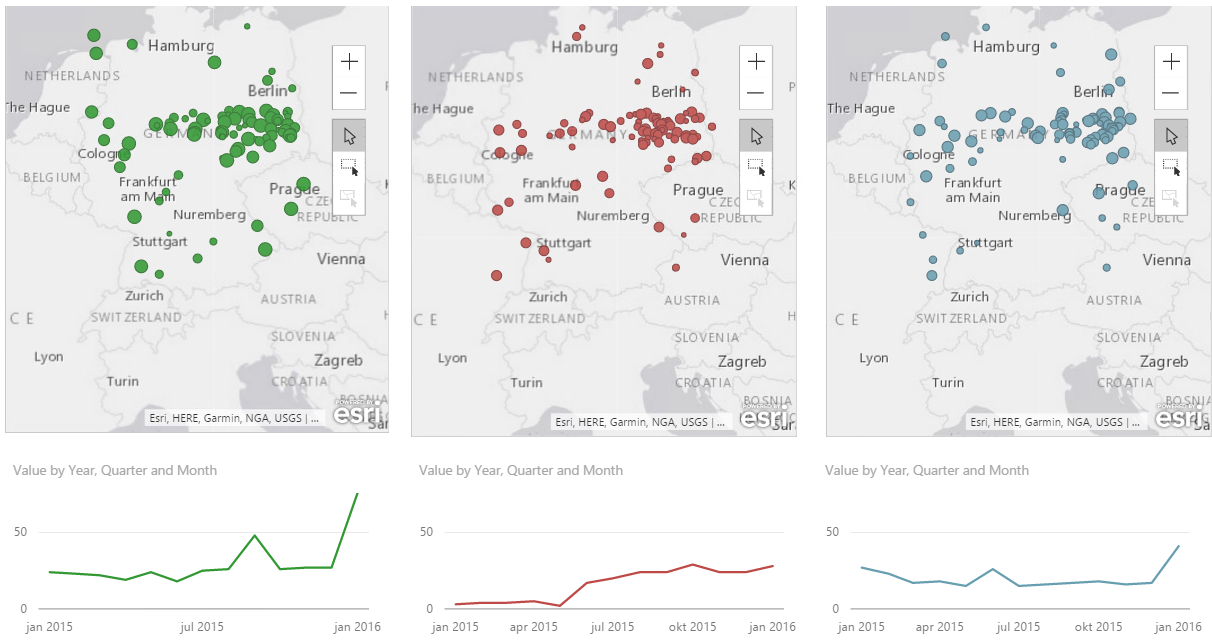
After doing this for all for files I know have a table with all terms and data for each year and I am free to use whatever tool I’d like to visualize it, f.ex PowerBI or Datazen, or since we’re in SQL Server 2016 now we can make a mobile report in SSRS. I chose PowerBI for now and added a calculation for percentage and also added year as a date to produce this.
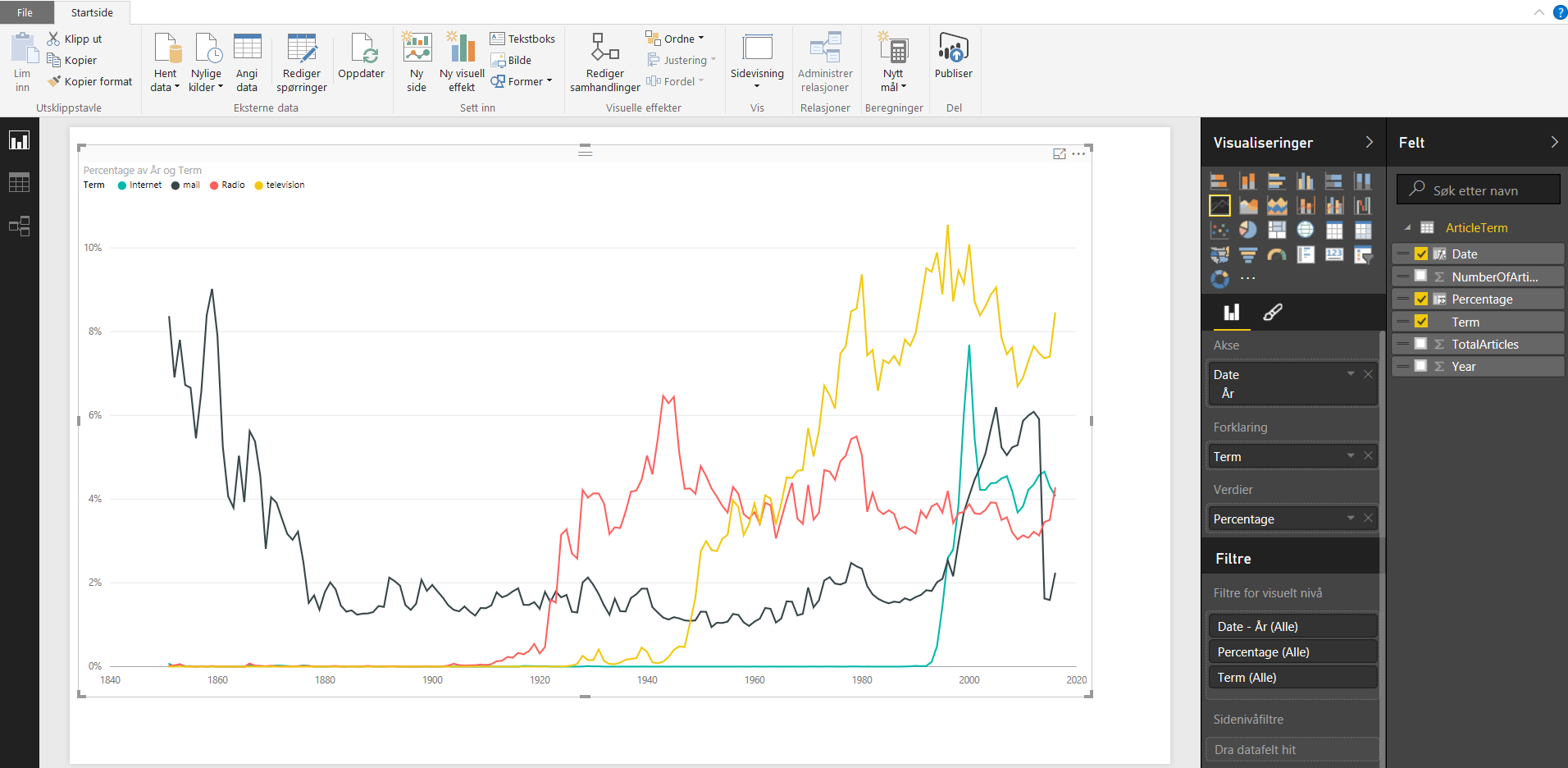
Lastly, not sure if fun fact worthy, but if you would have used the OPENJSON directly on graph_data you will be able to see the key and datatype of the other elements and from this you will see that you would have to use JSON_VALUE for the key term, while the JSON_QUERY for the key data since it is an array. All in all I think these JSON functions is a great addition to SQL Server in 2016, I am sure I will be using them quite a bit!