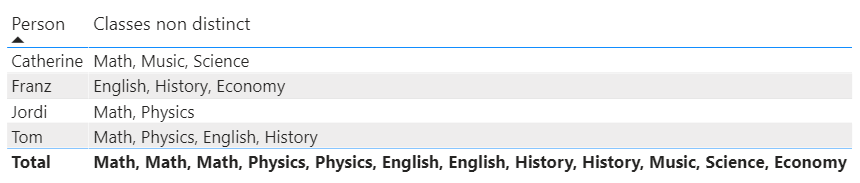
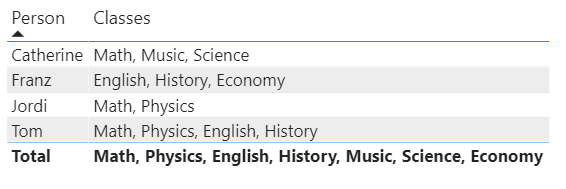
Lets be honest, I don’t think any of us will forget the year 2020. The year where home office became the norm for most. The year where extroverts turned crazy. The year where we all got to spend way to much time with ourselves. The year where we, or at least I, started realizing what actually means something for us.
The Ups!
For me 2020 has had its ups and downs. Lets start on the upside
- Moved into a new house in March
- Got a new job in April. Onboarding on Teams was an interesting experience. It worked nicely though!
- Done a lot of interviews, met cool people, learned about their journeys and experiences, and even hired a couple of great people!
- Started using Notion as my new note keeping tool. (OneNote, I am sorry, but I will never return to after this)
- Spent a lot of time thinking about graph databases, and boy am I looking for a project to use them!
- Made quite a lot of music. Such a good way of relaxing and getting lost in something completely different than most of my days
- Started playing a lot of disc golf on my local course
- Stayed healthy throughout the entire year!
- And probably a lot more than gets lost in a summary like this.
I’ve always known that I enjoy my own company, and 2020 has made this pretty clear. I don’t think I’ve struggled all that much with home office, not having to many social encounters and having to stay home in general. I love my wife and children, and I think having them around also has made things easier this year, perhaps with the exception when our kindergarten had to shut down. That was some interesting weeks.
Still, I am able to find joy, energy and excitement about stuff while being alone. I guess I have been able to get to know my inner introvert a lot more, it is interesting to sit alone and think about projects, music and completely unrealistic projects. I do miss hanging more out with my closest friends, but a video meeting on Teams/Whereby/Google hangout works as well while we wait for things to get back to normal.
2020 Realizations
I’m not gonna make a list of the downs that has happened in 2020. What I would like to think a little bit more about is which realizations I’ve had this year, and what I am noticing is becoming more important to me, both in my career and in my personal life.
Values
Which values means something for you as a person? I am realizing that more and more of my choices in life is being done after which values I set high. And I keep trying to do even more based on them. To make sure I can stand by every decision I make also when I in the future look back at them. And even though I would like to be in a place where we all have the same values I understand that not everyone have the same values that I have so it is also important for me to be open and listen to those people to see if I can learn something new.
Respect for others
What is respect? That’s a big question. For me the important thing is to not judge people based on their experience, looks, sex, race, or whatever really before you have met properly. This has hit me personally quite hard during parts of my work this year. I am not always comfortable with having to have Norwegian as a requirement for the positions that I have been hiring for. Still, I don’t think I can remove this completely because I need to make sure the people I hire can get good, interesting and challenging projects at our clients. So if they require Norwegian I feel locked by this at times.
Respect peoples time, respect peoples ideas and judgement. Respect that other people are different than you.
Diversity
I am a privileged individual. I’m a white male, born in Norway. I’ve had a safe childhood. I’ve been allowed to do the things I’ve wanted to. I have a good, safe job. And even though I have known this for so long I have in 2020 really started to feel this a lot harder by seeing, and actively searching for, what goes on around the globe. I really want to be able to find a way to make a personal contribution to make the world a more diverse place to live in 2021. And even though I don’t think it will be a massive impact I do believe talking about it, and doing even the smallest things can at least push things in the right direction. I also do realize that this will not be an easy task. Even trying to diversify who I follow on Twitter is an interesting task.
Failing ≠ Failing
I remember I had a goal before 2020 started to be less critical of what I put out on the internet. I think I was able to do this in some areas, like music, but I know I haven’t been as good on other areas as I would have liked to. This blog should have gotten a lot more posts if that was the case. To me perfection is a complete illusion. If you always aim for perfection you will never reach it. My wife and I have started to joke about that I believe mediocrity is perfection. And even though I don’t really want a mediocre life or work at a mediocre workplace I never think anything have to be perfect. I think if we aim for perfection we put restraints on ourselves and might miss ideas and possibilities that might be better or at least teach us something on the way. The goal should never be perfection. I think the goal should be to allow ourselves to test, fail and reflect while being on the journey for something better.
Priorities
I think the one thing that changes for everyone when you get a child is your priorities. Because even though you before perhaps prioritized work, exercise, friends or whatever, there is suddenly a small human being that needs to be priority number one! I do believe I have my priorities in the right place, at least for where I am now.
At the same time I try not to think about things like for example work/life balance. Work is part of who I am. I enjoy reading things I can use directly, or think I might need in the future, on my spare time. The one thing I am working on, and is getting better at, is physically putting my phone somewhere else when I don’t want to be bothered by it. If I am going outside with my kids I will most likely leave my phone inside. Eating a meal? I am placing the phone in the kitchen so I can’t reach it while I am eating.
I won’t spend 20 hours of my day working, and I don’t want to keep track of how many hours I do work. There is a thin line between my work life and personal life and I am fine with that. My family will always have priority, I know that and I make a point of making sure my family knows that. So if things get busy at work, well that will have replace some my own personal time, not the quality time with them. You can do a lot of good work, and thinking, while playing disc golf for example! Priorities are important, and even though I have my own list you might have a completely different one and that is okay!
Reflection
This write up is really just one big reflection of the entire year. I try to reflect both on work and personal life. I can do it on a monthly base, weekly based, and also down to for example each meeting I go out of or situations where I notice that someone around me perhaps reacts in a way I was surprised about in order to see what happened and if I could approach those situations in another way. There is a reason why I think the retrospective when doing agile development is the best, and possibly most important, thing to do. It allows us to focus on how things are being done, and not only look at what needs to be done.
Wrapping Up
2020 has been a strange year. And I don’t believe the first half of 2021 will be any different, other than the fact that we know a little bit more of what to expect. All we can do is try our best to keep in touch with those around us that needs a check in here and there. To reach out and ask people how they are. And for me I am going to try my best to do the small things I can do in order to make the world a little bit better while still challenging myself and take care of the people around me!
Stats
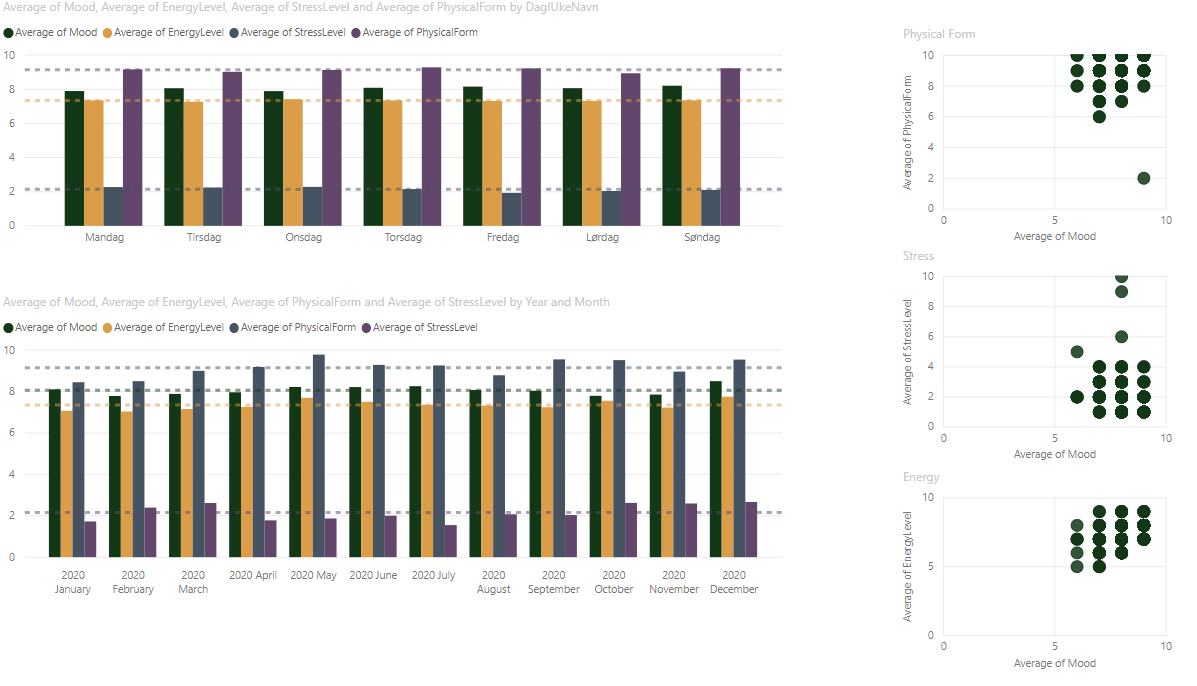
- I registered my end of day stats on 329 days of 2020. Pretty good!
- Day with best mood: Sundays
- Most energy: Wednesday
- Most stress: Wednesday
- Best physical form: Thursdays